文中截图来自我的幻灯片。另外我试着挑战了一下 Paper Mario 的主题风格,希望大家喜欢。
- VueConf 24 CN 官网:https://vueconf.cn/
- 在线幻灯片地址:https://jinjiang.dev/slides/my-10-years-with-vuejs/
- 演讲 B 站视频地址:https://www.bilibili.com/video/BV16W421R7ga/

一转眼,Vue.js 已经十周年了,这同时也几乎是我个人参与 Vue.js、参与开源项目的十年。
我和 Vue 缘分的开始应该是自己 2014 年在阿里内部创建的一个项目,名字如果没有记错的话叫 lib-noble。这个库算是一个 data observer 的 JavaScript 实现,后来我们管这种东西叫 reactivity API,再后来叫 signals。在我看来大同小异。写了这个库没多久,我就在 GitHub 上发现了 Vue.js,其中数据处理的相关设计和实现都跟我自己写的东西不谋而合。我当时的第一反应是,这个库比我写的好多了,而且还有很多其他功能,比如组件系统、模板编译等等。于是我就开始关注 Vue.js,并一路参与到了今天。
在这十年里,Vue.js 本身,包括团队,都经历了很多事情。我自己所经历的故事,已经出圈且被大家熟知或调侃的,也许就是自己在 Vue 的第一个 PR (只改了两个空格)、维护中文官网 (今年愚人节我们玩了个“威优易”的彩蛋)、创建了开源项目 Weex 并和 Vue 有一段时间的双向官方合作、以及在 Vue 的纪录片中出镜等等。相关的内容不打算赘述了。这次我主要想分享几则背后发生在 Vue 和我自己身上的小故事。尽可能还原一个更加立体的历经 10 年的开源项目。
]]>文中截图来自我的幻灯片。另外我试着挑战了一下 Paper Mario 的主题风格,希望大家喜欢。
- VueConf 24 CN 官网:https://vueconf.cn/
- 在线幻灯片地址:https://jinjiang.dev/slides/my-10-years-with-vuejs/
- 演讲 B 站视频地址:https://www.bilibili.com/video/BV16W421R7ga/
一转眼,Vue.js 已经十周年了,这同时也几乎是我个人参与 Vue.js、参与开源项目的十年。
我和 Vue 缘分的开始应该是自己 2014 年在阿里内部创建的一个项目,名字如果没有记错的话叫 lib-noble。这个库算是一个 data observer 的 JavaScript 实现,后来我们管这种东西叫 reactivity API,再后来叫 signals。在我看来大同小异。写了这个库没多久,我就在 GitHub 上发现了 Vue.js,其中数据处理的相关设计和实现都跟我自己写的东西不谋而合。我当时的第一反应是,这个库比我写的好多了,而且还有很多其他功能,比如组件系统、模板编译等等。于是我就开始关注 Vue.js,并一路参与到了今天。
在这十年里,Vue.js 本身,包括团队,都经历了很多事情。我自己所经历的故事,已经出圈且被大家熟知或调侃的,也许就是自己在 Vue 的第一个 PR (只改了两个空格)、维护中文官网 (今年愚人节我们玩了个“威优易”的彩蛋)、创建了开源项目 Weex 并和 Vue 有一段时间的双向官方合作、以及在 Vue 的纪录片中出镜等等。相关的内容不打算赘述了。这次我主要想分享几则背后发生在 Vue 和我自己身上的小故事。尽可能还原一个更加立体的历经 10 年的开源项目。
一、阿里巴巴西溪园区星巴克
时间:2015 年 1 月 5 日

背景是一个工作日的下午,尤雨溪来阿里巴巴西溪园区和团队分享介绍他的新项目 Vue.js,那也是我在团队内部推广 Vue.js 的时间点。分享结束后,我们和另外几个阿里的同事一起去星巴克闲聊。
我们讨论了很多技术相关的话题,另外印象最深刻的是,我通过尤雨溪的介绍认识了很多讨论技术的国际化的社区,这在我之前的工作习惯中是很少接触到的。这也对我后来参与开源项目、通过国际化技术社区了解和交流技术有了很大的帮助。
拥有一个开放的技术视野,对于一个开发者来说是非常重要的。这也是我在与 Vue.js 的十年中的一个不大不小的收获。
二、和天猫谈框架选型
时间:2016 + 2017 连续两年

当时我是阿里无线事业部的前端架构负责人,得知天猫前端团队有一个框架选型的窗口,于是试着推荐了一下 Vue.js 给他们。我们第一次谈的时候是 2016 年末,当时天猫前端团队对 Vue.js 的主要质疑是基础功能层面的,比如是否可以支持 IE6 之类的问题。我因此也和小右做了简短的交流,发现其实是有机会的,比如通过 VBScript 做一个数据监听的兼容层。我们还围绕 Vue.js 的一些别的特性做了讨论和交流,但很遗憾的是最终天猫前端团队还是选择了另外一个框架,那个框架的名字叫做 React。这是我们第一次就框架选型进行的交流。
虽然交流结束了,但对于我个人推广 Vue.js 的尝试来说,这只是一个开始。2017 是 Vue.js 快速发展的一年,不但发布了全新的 2.0,同时 Weex 这个项目也宣布开源,和 Vue.js 展开全面的官方合作。2017 年末,听闻天猫前端团队又有一个框架选型的窗口期,我决定跟他们再谈一次。这次的交流更多的是关于 Vue.js 的生态和社区,但仍然是充满了各种质疑,比如天猫方面觉得当时 Vue.js 的生态不够完善,谈话再一次陷入了僵局。我当时觉得完全没有办法改变天猫对 Vue.js 的感官,这次可能又要败兴而归了,临走之前我还是不甘心,甩下了一句接近是发牢骚的话,我说你看去年你们在担心 Vue.js 的特性,我们用了一年时间证明框架的特性完全不再是问题;今天你们再次担心 Vue.js 的生态和社区不够成熟,我虽然没有办法立刻回答这个问题,但我敢打赌,明年我们再见面的时候你们不会再问这个问题了。这段话说完之后自己扬长而去。
后面发生的故事大家可能都知道了,天猫前端团队稍后决定选择 Vue.js + Weex 作为天猫前端的主要框架。
这次“争取客户”的经历让我印象深刻。和我们平时在公司做的项目不同,开源项目的用户不是天生就有的,而且没有专业的市场和运营团队替你做这些事情。唯有自己不断去主动地、反复地争取,才会有转机出现,才会有真正的用户。这是我参与开源前所未有的体验之一。
三、阿里食堂一顿普通的工作餐
时间:2016 年末

当时已经是我在 Weex 团队的末期了,和 Vue.js 的官方合作也进行了一段时间。我和自己当时的主管一起在食堂排队打饭。因为队伍很长,我们俩闲来无事,就随便聊天。在谈论到一些工作上的问题时,我在想也许这是一个不错的时机,就把自己心里憋了很久的一段话说了出来。我说自己其实不得不坦承,做开源做到现在,心态已经逐渐发生了微妙的变化,虽然深知自己是阿里的员工,但归属感更加倾向于开源本身,而不是公司,这是一种近乎本能的感受。我的主管听完之后,没有说什么,意味深长地点了点头。
我想说,我们很多人对待开源,都是在自己有工作的基础上利用从业余时间起步的,也许或多或少都经历过这种做事方法和意识形态上的挣扎。当矛盾和冲突出现的时候,是什么让你处于纠结的位置?你会本能地站在哪一边?自己如何分配自己的精力?这些问题,我想,是每一个参与开源项目的人都会遇到的。我把这个称之为开源人的“身份认同”感。
四、微博上的(激烈)争论
时间:2017 年 8 月

也许人们已经逐渐忘记 2017 年 8 月前端圈发生过什么样的争论,那个时候 Vue.js 逐渐走入了主流的视野,伴随而来的是很多人的挑战和不屑。
我得说,简中互联网一直就不是一个和谐的存在,很多言论都充满了攻击性。在那个时期,每个人的价值观、表达方式、看问题的角度都是不同的,这种差异在互联网上被放大了。我也因为一些言论而被人攻击,也可能不经意间冒犯到了别人。但发生在那段时间对 Vue.js 和小右本人的争论,非常火爆而惨烈,而且看不到收敛的趋势。最后这件事情已经严重影响到了当事人正常的生活,而小右也不得不被老婆没收手机,通过这种“非常规操作”,整件事情才告一段落,大家也才逐渐冷静下来。
当时大家具体的讨论内容,我们今天不必多谈,因为 Vue.js 通过这么多年的发展已经把各种争议逐一摆平。但在那个时刻,作为一个开源项目,当你被更多人看到的那一刻,也就是会被更多人拿起放大镜审视的一刻。这是一个槛儿,一条长征路上的必经之路。
同样地,如果只跟自己公司的客户打交道,你可能永远也不会想到,作为一个开源项目,你无时不刻会遇到各种各样的人,你甚至不知道他们来自哪里,但却需要面对他们的每一个问题和质疑。这是做开源的另一门必修课。
五、在 Vue Fes Japan 碰面
时间:2018 年 11 月 3 日

这是我第一次去日本参会,也是我第一次参加 Vue.js 的一个国际性的大会。我在会场里碰到了很多来自世界各地的开发者,他们对 Vue.js 的热情和专业程度让我印象深刻。
那次会议给我印象最深的其实是我和小右在会后的一次交流。在那次交流中,我们聊了很多关于个人和项目长期发展的话题,比如要有长期的规划,要有壮大团队的准备,要有合理的经营模式等等,包括“被动收入”这个词,就是我第一次从这次交流中听到的。
这让我想到,做开源,不是把源码放到 GitHub 上就完事了,而是需要有一个长期的规划和经营。这个规划和经营,不仅仅是技术上的,还有很多其他方面的,比如社区、商业、生态等等。
六、一个周末下午的上海
时间:2016 年夏

那个时候我还在 Weex 团队,和小右的合作已经进行了一段时间,我们在上海的一个咖啡馆里见面,本身是聊 Vue.js 和 Weex 集成的一些技术细节,但聊完工作之后,大家都还有些时间,就继续闲聊了很多别的技术。印象中同行的还有 Hax,一位非常资深的同行,后来成为了国内为数不多的 TC39 成员。
那是我们接下来无数次讨论打包构建工具的开始,当时 webpack 已经变成毫无争议的主流,但性能和复杂工程的配置问题也逐渐变成了前端工程家家户户难念的经。同年 Rollup.js 也开始崭露头角,我们也讨论了很多关于 Rollup.js 的优势和劣势,以及它和 webpack 的区别。后来大家都知道了 Vite 的诞生,从我的视角来看,Vite 的诞生看似是一次偶然的尝试,但实际上是一个长期的技术积累和思考的结果。直到一个基于上述的创新的想法被证实,才会被大家看到。
有的时候做成一个开源项目,不是因为你知道的东西更多,而是因为你在大家都知道的地方,产生了独创的智慧的想法,做了一些别人没有做到的事情。你需要一双慧眼,哪怕只是改变这个世界一点点。
七、开源赞助都蒸发了?
时间:2023 年 3 月
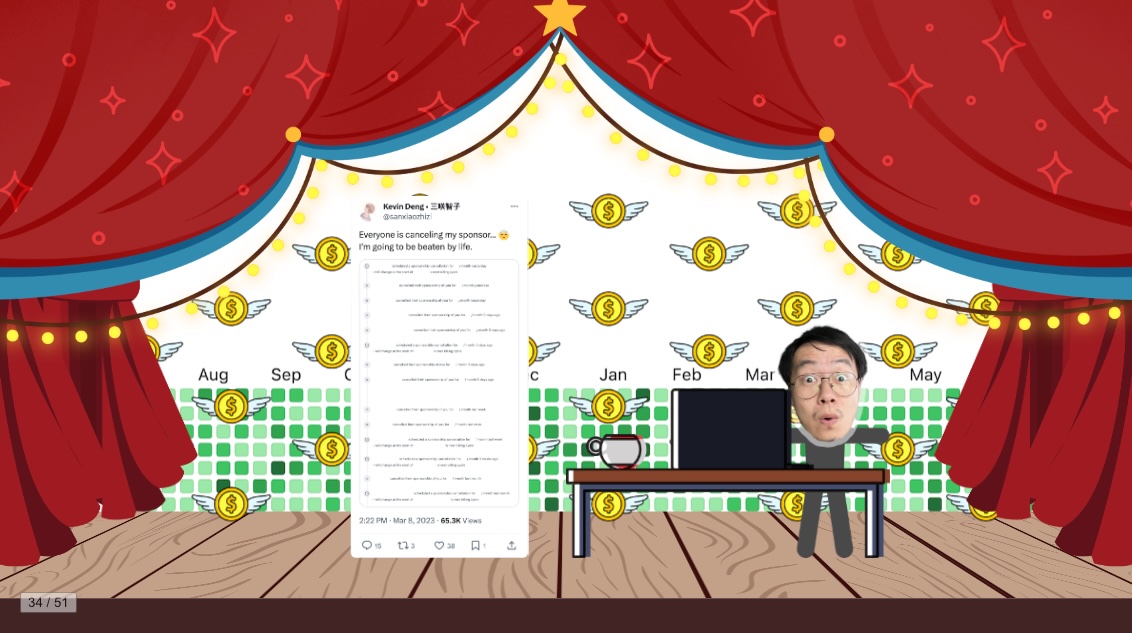
时间来到去年春天,当时 GitHub Sponsor 终止了对 PayPal 的支持,导致我周围很多以接受社区赞助为主要收入来源的开发者都遭遇了一次收入的大幅度下降。很多人都在网上晒自己损失掉的赞助,或表达各种负面的情绪。
我虽然严格意义上不算是靠开源赞助谋生的开发者,但我看到周围的朋友都在失去赞助,心里也特别不是滋味,觉得应该做点什么。于是决定在社交平台上号召更多人加入到赞助的行列。我自己也开始在 GitHub 上赞助自己周围的开源人,虽然不是很多,但我希望能通过自己的实际行动给社区提提气,也希望这是一个好的开始。
通过这次经历,也让我设身处地的感受到,很多开源项目的维护者,尤其是那些靠开源项目谋生的人,他们的生活其实并不容易。即便是那些大名鼎鼎的开源项目,维护者的收入也随时处在不稳定的状态,这种不稳定的状态和不安全感,是我们习惯在大厂上班,有固定的薪水和五险一金,甚至年底还能拿大红包的人所无法体会的。
八、在新加坡的不期而遇
时间:2021 年至今

我和小右两家人都先后搬来了新加坡,也许你和我一样曾设想过,我们两个每天待在新加坡的某个咖啡馆里讨论技术的场景。但实际上是,我们每次见面绝大部分的话题都是技术以外的琐事,比如如何带小孩,如何管理好自己的时间,当然偶尔也会一起打打游戏看看比赛之类的。
更近距离和小右接触下来,我觉得小右对我来说已经不仅仅是技术上的同行,而更像是生活上的伙伴,一个活生生的人。这种人情味,是我们在 GitHub 上看不到的。但这也让我想到,开源项目的背后,其实都是这样一群人。大家一开始做开源也许只是一个简单纯粹的动作。随着时间的推移,逐渐拥有更多自己的生活、家庭、甚至上有老下有小之后,做开源不再那么简单,而变得复杂。这是难免会遇到的、同时也是需要我们正面面对的问题。
总结

其实除了上述这几则故事,这 10 年间发生在 Vue.js 和我自己身上的珍贵回忆还有非常多,包括项目的 GitHub star 一路飙升,超过别的我们之前仰慕的开源项目的时候;包括每次有大公司宣布选用或赞助 Vue.js 的时候;包括每次新版本 Vue.js 发布的时候;也包括每次参加的团队线下聚会;也包括每次新人加入、旧人离开;这些都是我这 10 年来参与 Vue.js 的一部分。每一段旅程都有值得细品的独一无二的内容。
然而我选择上述这八则故事的原因,是我觉得他们充分体现了五个字:开源之不易。

开源之不易,不仅仅是技术上的高瞻远瞩和灵光乍现,还有很多其他方面的。开源之不易,是因为你需要不断地去争取用户,去解决用户的问题,去回答用户的质疑。开源之不易,是因为你需要不断地去面对各种各样的人,去解决各种各样的问题。开源之不易,是因为你需要不断地去思考未来,去规划未来,去经营未来。开源之不易,是因为你需要不断地去适应变化,去接受挑战,去面对困难。
所以,每次回首 Vue.js 走过的十年,我越来越觉得,这是一段不易的旅程,也越来越庆幸自己能够参与其中,更由衷地感谢所有支持 Vue.js 的人。

在前端技术快速发展迭代的今天,你也许会觉得一个 10 年的框架已经算是“老掉牙的框架”了,但我觉得 Vue.js 并不是,引用我特别喜欢的电视节目《圆桌派》中的一句话:“心中有大志”。如果心中没有伟大的志向,那人才是真的老了。我想说,Vue.js 在 10 年后的今天,依然活力十足,我们有非常多年轻有为的新鲜血液不断加入,也一直在推出新的特性和工具,包括不仅限于这次 VueConf 上介绍的 Vapor mode、新版 DevTools、当然也包括新的 Vite 和 Rolldown 等等。我们有理由期待 Vue.js 的未来。

也希望大家可以跟 Vue.js 一起,再战十年!
]]>






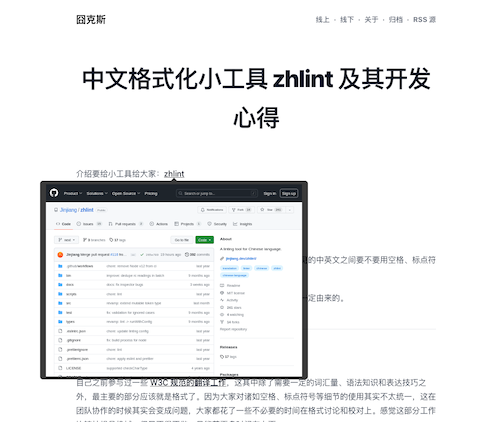



 Image by
Image by  Spike Jonze’s film “Her” provides an interesting prediction for how we might interact with computers in the future.
Spike Jonze’s film “Her” provides an interesting prediction for how we might interact with computers in the future.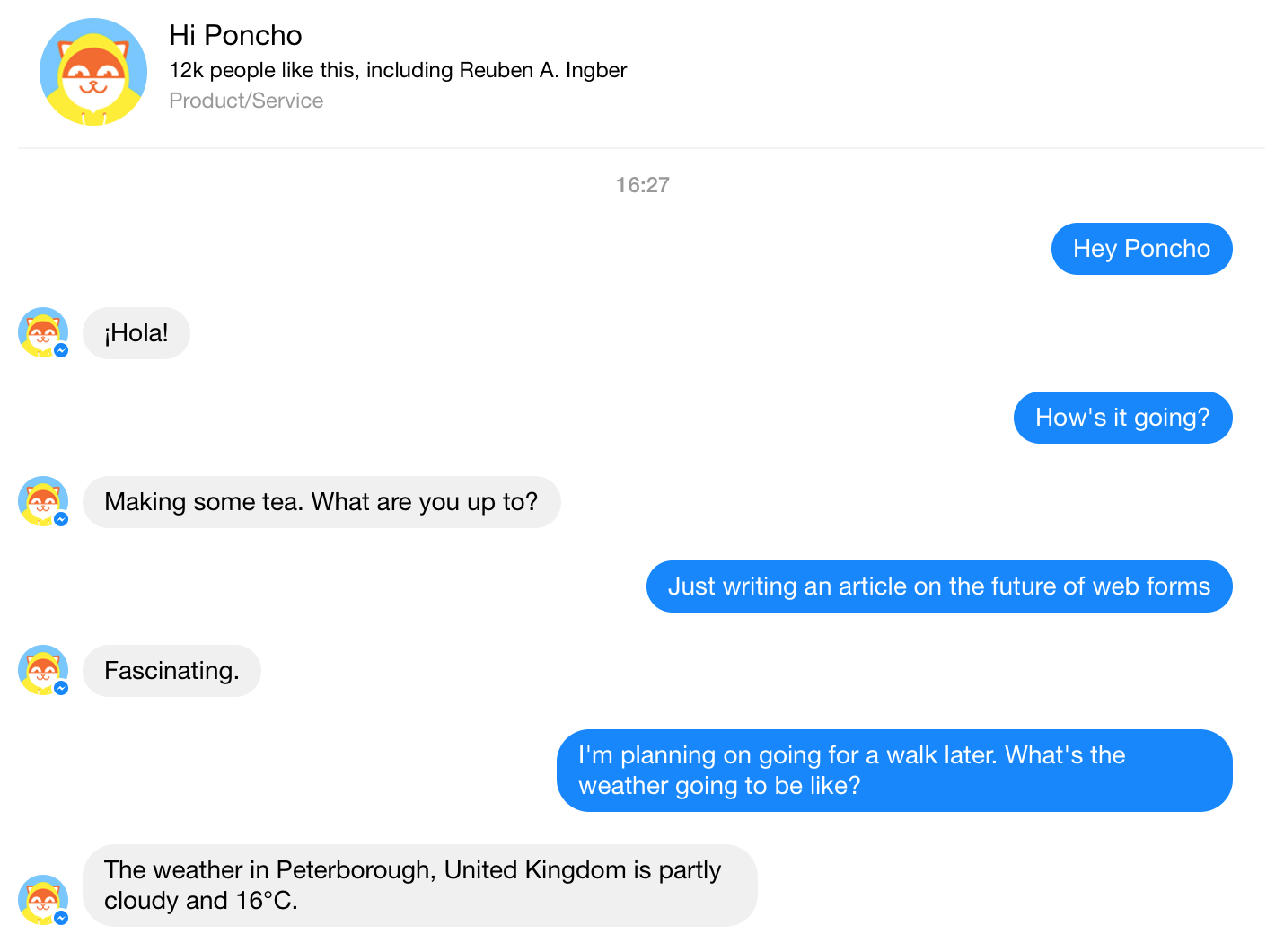 A conversation with Facebooks chat bot “Poncho”.
A conversation with Facebooks chat bot “Poncho”. The “Get a Quote” page from
The “Get a Quote” page from 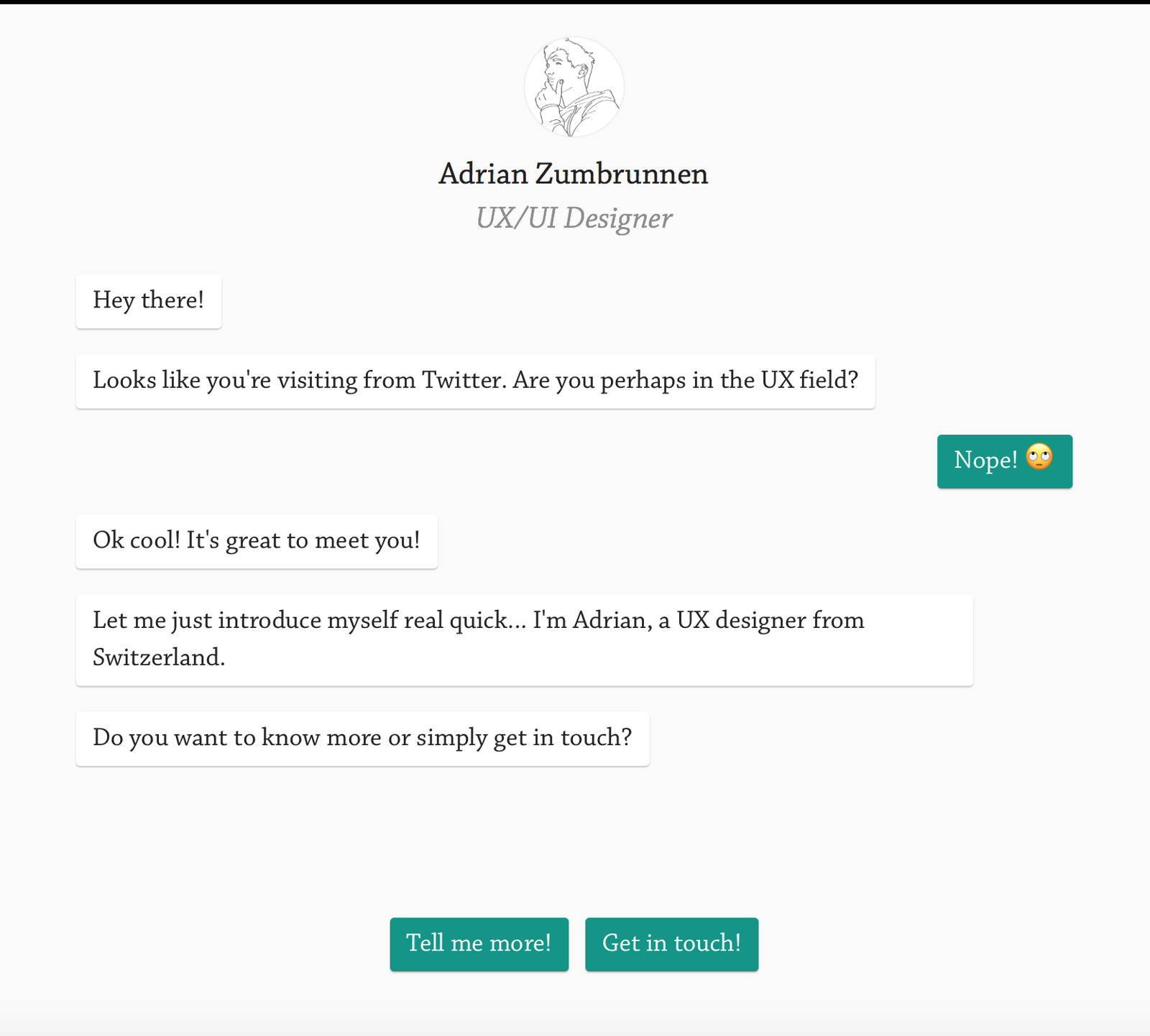 Adrian Zumbrunnen’s conversations website
Adrian Zumbrunnen’s conversations website 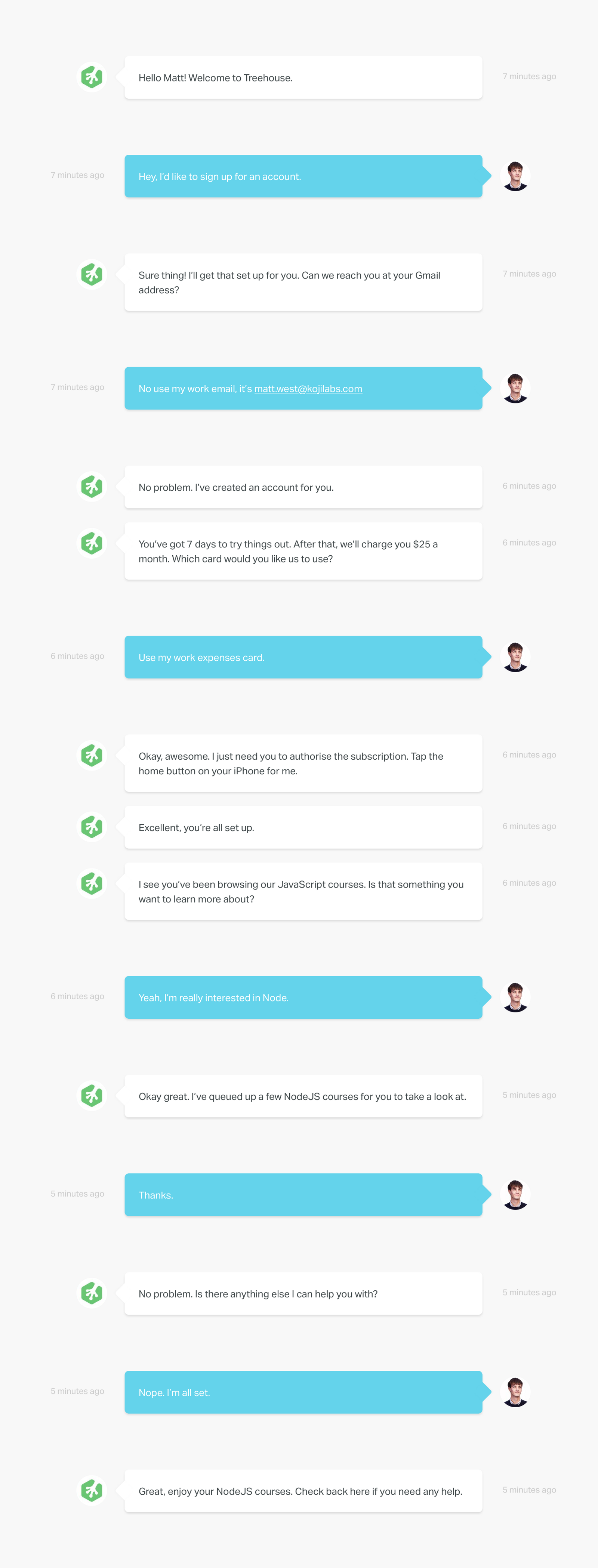 What would the sign up flow look like if we moved beyond forms?
What would the sign up flow look like if we moved beyond forms?











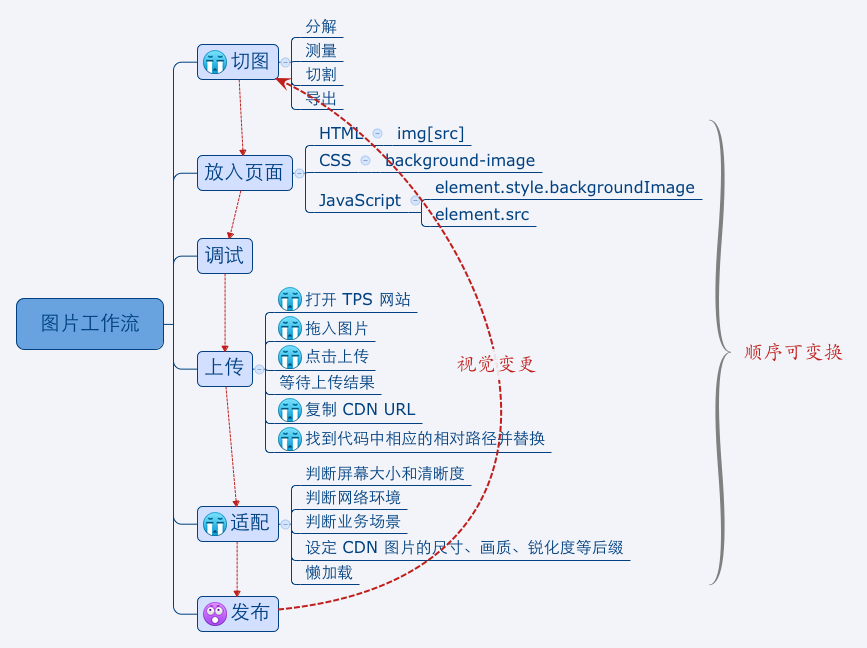


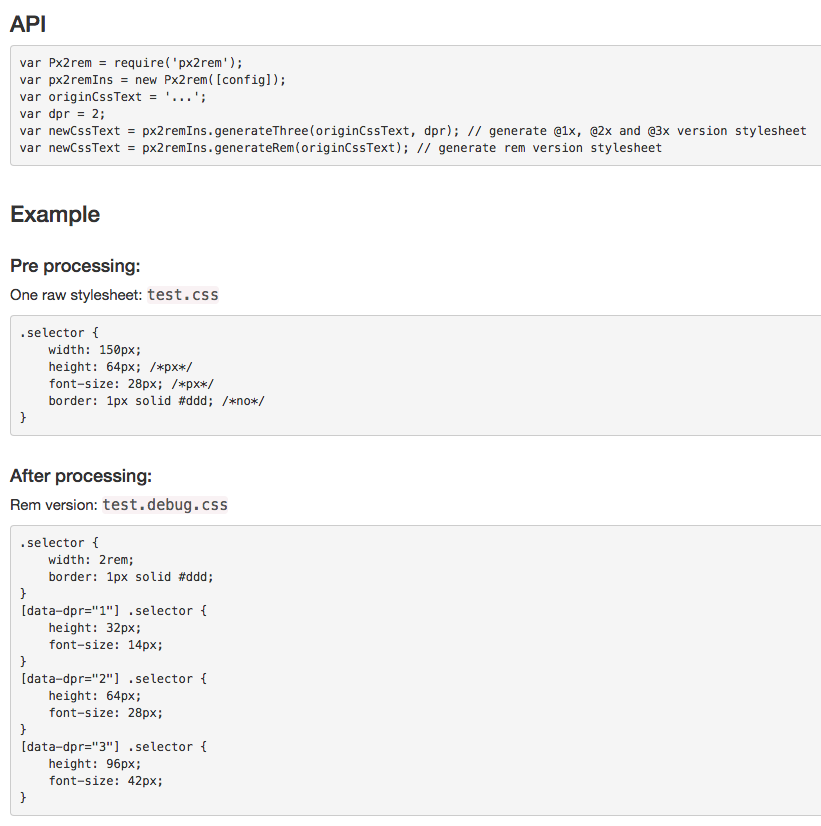
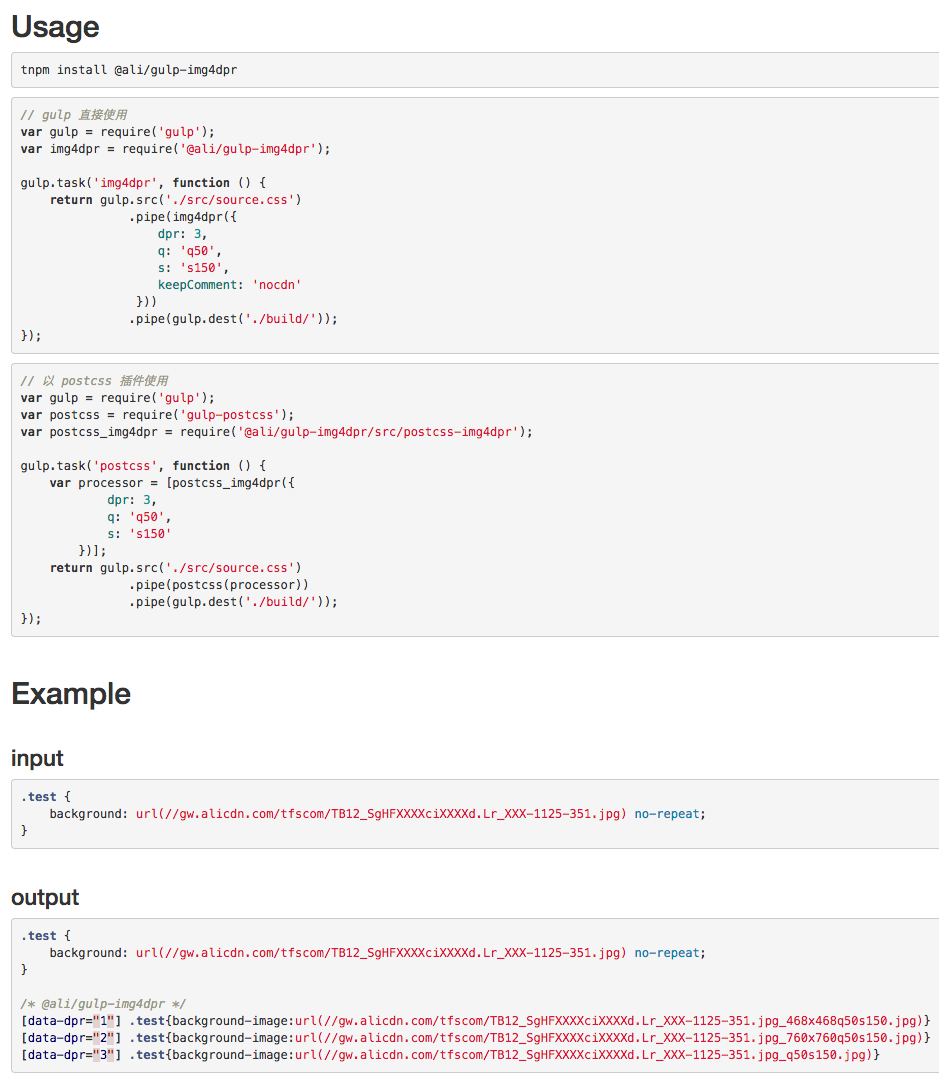



























































































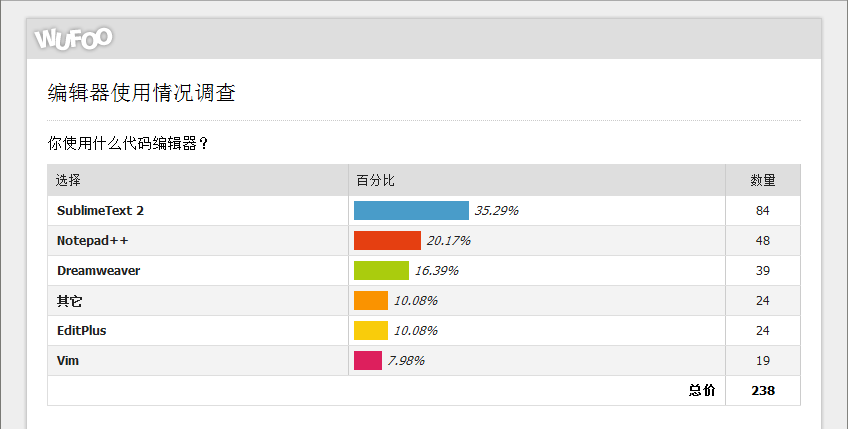
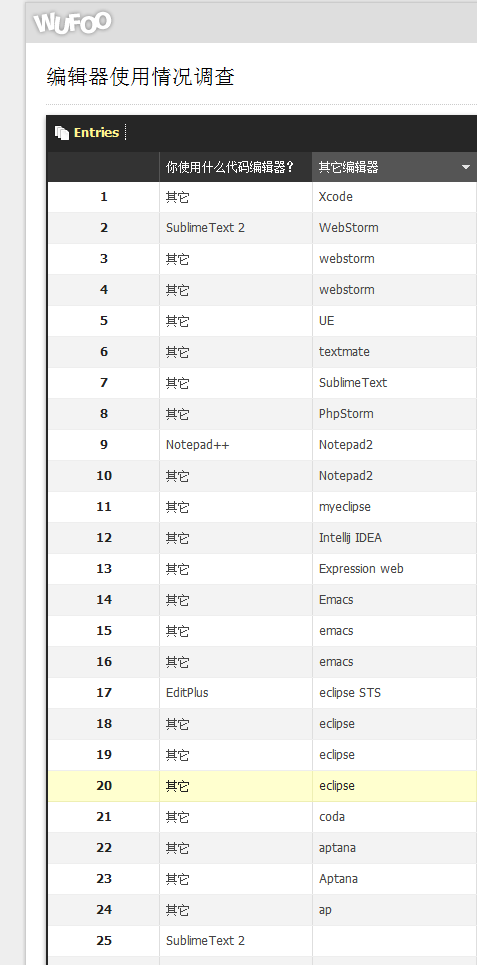



















 图片来自和讯新闻
图片来自和讯新闻



























































![webrebuild.org第四届年会-北京站[2010.07.17]](http://webrebuild.org/y/beijing/2/img/468x60.jpg)