囧克斯
这里是勾三股四的家
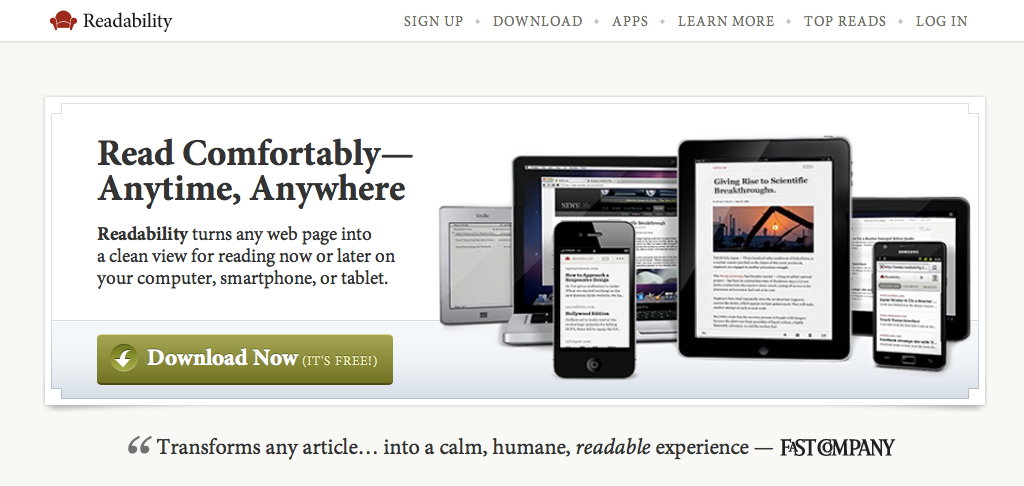
HTML5峰会归来
这次 @HTML5梦工场 的活动真是太棒了!我们了解企业,了解同行,了解技术,了解趋势,吃喝玩乐,雅俗共赏,天南海北共聚一堂,还有什么活动能跟这样的 #html5峰会# 相媲美呢?!虽然2天脚都站酸了,但真心觉得值!
了解企业
这次峰会上,诸多企业都在会场搭建了属于自己的展台:有浏览器,有应用平台、有技术图书出版社,这样不够,后台技术来了,电视来了,物联网来了,广告服务来了,这样还不够,更夸张的是眼镜和糕点也来了。其实仔细想想,中间这部分领域是早晚要和HTML5打交道的,而后面这部分呢,也几乎是每一个前端工程师生活的一部分(你看,干这行的视力都不太好,还经常以庆祝xxx为借口买蛋糕吃)。我们了解形形色色的行业和企业,体验工程师生活的每一部分。
当然说到企业展台,这也包括我的老东家傲游。今年公司启动了全平台的浏览器研发项目,除了已经有的PC、安卓版本,还陆续发布了Mac、iPad、iPhone版本。所以这次的展台内容很丰富,有些朋友甚至来到展台前把所有的设备都试用一遍,才意尤未尽的离开,这让我们这两天“辛苦站台”的同事们倍感欣慰。

了解同行
我想说第二天的HTML5作品展真棒!一口气看58份优秀作品,结识58组前端精英,感受大家的创意和热情!这次给我印象深刻的,有一个是用Canvas写毛笔字的,可以根据书写的速度模拟出毛笔的力道来,非常神奇;还有一个作品用到了最新的摄像头媒介接口,做出了类似Kinect的游戏体验,他们的作者自豪的说:“我们的目标就是秒杀Kinect!”;另外我非常有幸结识到了HTML5图形库ichartjs的作者,我觉得他的作品像一阵及时雨,刚好填补了图表制作这个HTML5非常大的领域空白。除此之外的其它作品也都各有千秋,看得出他们呕心沥血的投入和付出。

我也有机会展示了自己参与的一个开源项目:就是H5Slides,我们专门为了这次的峰会搭建了一个供大家试用和体验的网站。不少开发者也对我们的作品产生了浓厚的兴趣。还有些人在网上看到过,现场认出我来了,哈哈好害羞滴说!
分享bookmarklet一则:随意阅读
这款bookmarklet是我对主流阅读模式智能识别规则的一种吐槽。
当然,首先,阅读模式本身是一项非常棒的功能!他可以增强文章的阅读体验,统一不同页面的视觉风格。可以让人专注在文章内容中。等等。 而我要吐槽的点,是这个所谓的“智能判断文章内容”的算法。
“智能分析”的阅读器
阅读模式的核心任务之一,就是能够找出我们在各种凌乱广告、装饰物、页眉页脚之中的正文内容。在找内容这件事上,大家不约而同的使用了智能分析的路数。这里是早期开源的Readability脚本库的核心代码,我们可以看到其中包含着大量用来识别某dom结点是否是正文根结点的算法公示。而这套算法,又是从大量已存在的网页中归纳而来的。
阻力
既然是归纳的结果,而现如今已存在的网页已经数以亿计五花八门了,那不可避免的会存在判断误差。我们希望把内容识别的准确率提到最高,但会遇到一个问题:就是广告主、站长都有各自的小算盘,他们时刻准备着违背这些智能,降低判别的准确率,不让它正常工作,以谋取自己更高的收益或二次点击率。因此,这一智能的识别规则无法完全公开(Readability随后停止了开放源代码,我猜也有这方面的考量)。
how to enable?
可黑盒的智能规则又导致了另外一个问题:智能识别如果出现判断误差,对于那些希望支持阅读模式的网站,又无奈于找不到这些计算规则去适配。于是我们又会看到类似“how to enable safari reader”这样的问题满天飞。
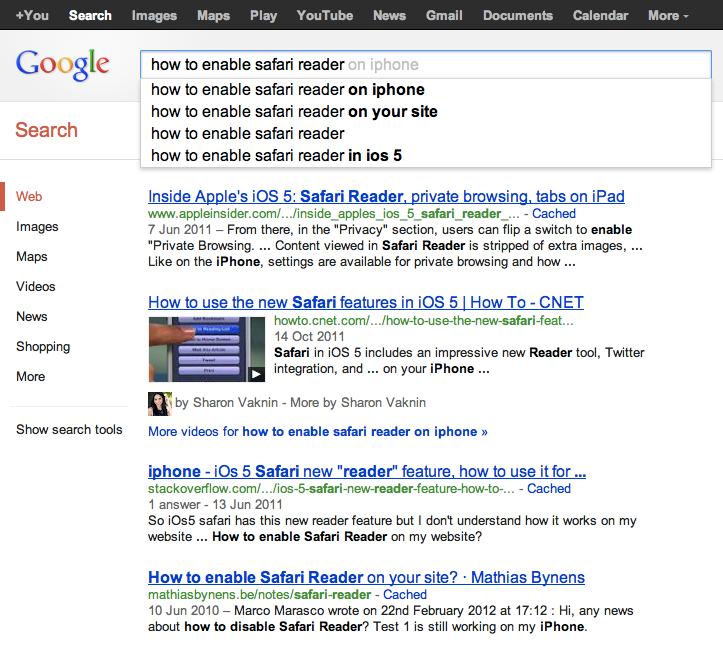
最后阅读模式的识别规则、支持者、反对者扭打在了一起。
国际羽联和中国队之间的恶性循环
直观的感觉是这次“冷”敦奥运会上,国际上对中国集体发难。这样的感觉起码有这些因素作祟:第一,自从北京奥运会中国在家门口历史上首次拿到金牌第一,国际媒体就开始越来越关注中国;第二,以前我们都陶醉在某些洗脑工具中,听不到国外的声音;第三,称赞中国的声音不够劲爆,我们的舆论也有选择性的把更多偏激的言论带回了国内;第四,新媒体全面占领传统媒体,消息更快速,也更不准确;第五,我们喜欢“拿来”,却不喜欢回馈。
 图片来自和讯新闻
图片来自和讯新闻
话说这次奥运会4对羽毛球选手被判消极比赛取消资格一事,绝对是国际羽联对中国长期以来忍无可忍的一次报复。毫无疑问中国现在在羽毛球这个项目上太过强大,尤其是女双,强大到对手连打败你的信心都没有了。这样的话选手的成绩在淘汰赛制中变得偶然性很大:第一轮就碰中国,名次肯定倒数,晚点碰中国,甚至可以拿奖牌。
我猜国际羽联把羽毛球由纯淘汰赛改成循环赛加淘汰赛,这也直接导致了这一出闹剧的出现。其实规则的改变就是给那些名次不好的人更多机会,给中国队更多危险。但我不认为这是一种良性的改变。
ZeroClipboard 学习笔记
如题,周末抽空学习了一下。
ZeroClipboard是在桌面电脑的浏览器上,通过flash技术实现“复制到剪切板”功能的一个程序。它的好处是可以兼容所有浏览器,完成剪切板的操作。
我们在使用的时候主要就用到两个文件:一个是js文件
ZeroClipboard.js,用来引用在网页中;另一个则是swf文件ZeroClipboard.swf,它无需我们在代码里引用,而是被之前的那个ZeroClipboard.js二次调用的。ZeroClipboard的工作原理大概是,在网页的“复制”按钮上层遮罩一个透明的flash,这个flash在被点击之后,会调用其的剪切板处理功能,完成对特定文本的复制。这里有几件事需要我们来完成:
- 创建一个透明的flash
- 将这个flash浮在按钮上层
- 确定要复制的文本是什么
- 监听这个透明flash的鼠标点击事件
- 该flash被点击之后,完成剪切板处理
对于这几件事,ZeroClipboard分别提供了不同的api,来完成整个需求。
“思考人生”
前几天欧洲杯,“巴神”巴洛特利一个散步式单刀被后卫回追成功,解说员戏称他停下来思考人生了,一时间“思考人生”变成了个热门词,以至于我们看到谁发呆、低头,都说他们在“思考人生”。其实我最近也在思考人生,也许比他们的严肃一些了。

来北京的第6年,同时也是在傲游的第6年,一转眼小半年快过去了。
这半年过得算是波澜不惊吧,事情异常多,公司的,家里的,亲戚朋友的,各种活动的,还狗屎运出了一趟国。总会有些事情照顾不周,处理不妥,也在意料之中。我只想说:感谢经历,你就自己想办法挺过去吧。
在这不到6年的时间里,我一直没有停止做一件事,就是不断努力发现自己的问题和不足,并尝试改变它——相信很多人也都会这样。这期间有些改变是令我兴奋的;有些事情是立竿见影的,富有成就感的;还有很多事情,在潜移默化的发生着,你无法通过一两件事情看清楚,但经过长时间的积累,暮然回首,你会发现,它真的变了,有好的也有不好的。
听杨东杰弹吉他
这是一个灰常活泼并且有怀旧感的标题。
原本打算记我上周末成都之行的一篇日志,我觉得除了参加HTML5梦工厂成都站的技术交流活动之外,最大的收获,莫过于同杨东杰童鞋的畅谈。另外今天连续在微博上看了两个罗纳尔多和萨内蒂年轻时候的足球集锦,突然觉得这几年间,很多事情在发生着悄然的改变,比如曾经有个美少女组合叫S.H.E,昨天在地铁外看到Ella的一个活动海报,才发觉,这个团早已淡出了我们的视野。我们上大学的时候,有几个舍友特别喜欢挺S.H.E,导致我也比较熟悉他们的歌曲,后来让我对他们真正产生印象的是《Play》那张专辑,觉得它的概念蛮有意思的,整张唱片都是轻松欢快的气氛。于是《听袁惟仁弹吉他》这首歌一闪而过,于是就有了这个标题……
有点扯远了