博客站迁移至 VitePress 的备忘
水一篇。这周集中把博客由 Hexo 迁移到了 VitePress,顺便把主题也换了。简单记录一下迁移过程。


根据我的观察 VitePress 目前用的最多的是文档站,比如 Vue 的官方网站、Vite 的官方网站、Rollup 的官方网站等。但是拿它来做博客站的不多,但也完全没有问题,比如 Vue 的官方博客。另外我还找到一个叫 vitepressblog.dev 的站点,它是一个 VitePress 的博客主题。对两者做了简单的比对之后,我觉得 Vue 的官方博客的主题更简单更适合我的需求,所以我就直接把源文件拿来用了。
主体迁移过程
我之前的博客内容主要分了四部分:
- 独立页面:比如“关于”页面,一共有三个
- 文章:有将尽 200 篇
- 文章导航:即文章列表页面和归档页面,按照时间倒序分页呈现,其实首页也算这个类别
- 静态资源:一些前端的小 demo,作为静态资源存在
我把这四部分进行了逐步迁移
先把独立页面迁移过来,这个很简单,把每个文件复制到相同的路径就好了
把所有文章都拷贝到新仓库的
blog目录,但不急于调试文章的展示页面,因为这些文章还暂时没有入口,所以我紧接着先迁移了文章导航实现文章导航。Vue 的博客站主题有一个明显的局限性,就是它的博客列表不支持分页。我这里运用的是 VitePress 自身的 Dynamic Routes 特性,在工程里同时创建了
page/[page].md和page/[page].paths.js来计算和生产分页信息。如paths.js的内容如下:jsimport { readdirSync } from 'fs' const PAGE_SIZE = 10 // 计算文章数量 const data = readdirSync('./blog').filter(x => x.match(/\.md$/)) // 计算页面数量 const pageMax = Math.ceil(data.length / PAGE_SIZE) // 创建分页参数 const pageParams = new Array(pageMax).fill(0) .map((_, i) => ({ params: { page: i + 1 } })) export default { paths() { return pageParams } }这样在相应的渲染组件里就可以:
jsimport { useData } from 'vitepress' // 这里的 `./posts.data.js` 和 Vue 博客站的实现相同,所以就不赘述了 import { data as posts } from './posts.data.js' const PAGE_SIZE = 10 const { params } = useData() const currentPosts = computed(() => { const { page } = params.value || { page: 1 } const start = (page - 1) * PAGE_SIZE const end = start + PAGE_SIZE return posts.slice(start, end) })同理,对于归档页面来说,也是对应的实现
archives/page/[page].md和archives/page/[page].paths.js,只不过PAGE_SIZE我定为了 100。另外我实现了一个简单的
Pagination.vue,用来实现文章列表页面上的分页器。代码很简单就不贴了。
接下来确保每一篇文章都能够被识别和渲染。因为我之前有些 blog 写得略随意,有些直接用 HTML 写的而不是 Markdown,且标签没有严格闭合和转码,还有些索性往文章里塞了一段内联的
<style>和<script>直接出 demo。这些细节在 VitePress 里多多少少都引发了一些解析错误,我也都逐个修复了。最后就是静态资源的迁移了。这个比较简单,直接把之前的静态文件拷贝到
public目录就好了。
经过了这些粗枝大叶的迁移之后,网站差不多可以跑起来了,内容也都正常展示出来了。接下来就是一些细节的完善和优化了。
细节完善和优化
首先是把模板里不必要的信息注释掉或删掉。Vue Blog 的模板里有一些我这里不需要的信息,比如作者、头像不需要,因为就我一个人写;另外我在写作的时候越来越希望内容本身经得住时间考验,不论是什么时候写的都值得一读,所以发布时间之类的信息我个人觉得干扰阅读,为了极致的阅读场景我把展示这些信息的组件也都拿掉了。同时布局方面我也把侧边栏拿掉了。这完全是我的个人偏好。

还有一个小细节是关于文章列表中每一篇文章的摘要,之前 Hexo 是通过寻找内容中的 <!--more--> 记号并以此为分界来截取摘要的,但 VitePress 中是通过 --- 来识别的,并且在我迁移的那一刻还没有支持自定义分界记号。所以我只能手动 (当然是批量处理的) 把文章内容之前的分界记号全部都改成 ---。不过好消息是我把这个问题提给了 VitePress 并很快得到了支持,最新的版本已经支持自定义分界记号了。大家如果再遇到这个问题就不用手动改了。相关 issue
再接下来是处理文章评论,这里有两部分,第一部分是早期我的博客基于 Typecho 的时候产生的评论,数据在 MySQL 里,当然这部分内容现在看是纯静态的了,不会再有更新了;第二部分是现在我的博客基于 Hexo 的时候产生的评论,数据在 GitHub issues 里,通过一个叫 gitalk 的库进行加载。后者相对容易,我把 gitalk 这个库导入评论组件的 <script setup> 里调用就可以了,并且监听路由改变,如果文章换了就重新初始化并加载对应的评论。
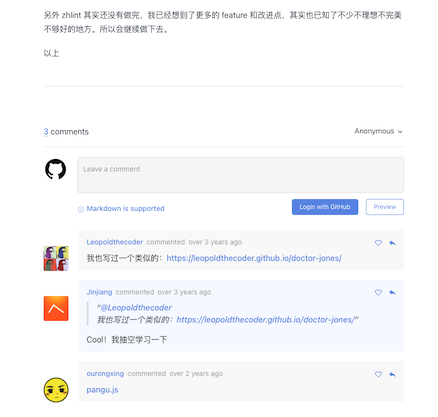
前者就比较麻烦了,因为我不想继续把 Typecho 的数据库挂在服务器上,所以我把数据导出成了 JSON 文件,然后在 transformPageData() 的时候把数据作为 earlyComments 灌入 frontmatter 元数据。这样在 build 的时候,每个页面都可以通过 VitePress 自带的 useData() 访问 useData().frontmatter.value.earlyComments 获取到这个数据,进而在页面上渲染对应的早期评论。

下一步是支持 open graph 之类的元数据。这里绝大多数信息我都是通过 config 中的 transformHead(context) 函数实现的。基本原理就是从 context.pageData 中分析出要展示的元数据,然后生成 <meta> 标签信息返回。但这里有三个特例:
description:首先 pageData 里没有现成的信息,所以我自己写了个很简单粗暴的函数,从文章对应的源文件中读取内容,提取纯文本,然后截断前 200 个字符作为描述信息。不算特别严谨,但反正我平时写作时对格式对运用也比较规矩,所以足够了。大概的实现我提取了一个函数tsimport fs from 'fs' import matter from 'gray-matter' import { markdownToTxt } from 'markdown-to-txt' export const genDescription = (filepath: string): string | undefined => { if (fs.existsSync(filepath)) { const content = fs.readFileSync(filepath, 'utf-8') const data = matter(content) const result = markdownToTxt(data.content.replace(/<[^>]+>/g, '')).replace(/\s+/g, ' ') return result.length > 200 ? result.slice(0, 197) + '...' : result } }description这个元数据 VitePress 本身也会生成,并且在我迁移的那段时间是不支持合并或覆盖的,导致页面生成出来的 HTML 里会有两段<meta name="description">。这个问题估计你们猜到了,我也提 issue 了,最新版已经修复了。但我在这个 issue 被修复之前采取了另外一个临时的解决办法,就是通过 config 里的transformHtml(code)字段,把多余的<meta name="description">标签删掉。tsasync transformHtml(code) { // dedupe <meta name="description"> const results = [] const regExp = /<meta name="description"[^>]+>/gi while (regExp.exec(code)) { results.push(regExp.lastIndex) } if (results.length > 1) { return code.replace(/<meta name="description"[^>]+>/, '') } },og:image/twitter:image这两个字段目前社区最热门的实现方式是在服务端根据文章信息渲染一张图然后返回 URL (进而让用户觉得反正都已经上 Node 了不然就全站 SSR 吧,或者说至少这个功能跑不掉了那肯定得上 SSR)。说得好像不用这种服务博客都没法写了一样。我冷静的想了想好像也不必,选了个自己能接受的笨办法,就是找个离线工具生成自己想要的缩略图放到静态资源目录,然后在 frontmatter 里手写一个 manual_og_image 字段指向这个文件就好了。所以最终我的博客站用的依然是纯静态服务器。
最终的 transformHead(context) 实现大概是这样 (其中 genMeta 和 getIdFromFilePath 逻辑并不复杂,也不是这里讨论的重点,就不展开了):
async transformHead(context): Promise<HeadConfig[]> {
// add <meta>s
const description = genDescription(context.page)
const title = context.pageData.title
const url = `https://jiongks.name/${getIdFromFilePath(context.page)}`
const published = context.pageData.frontmatter.date
const updated = context.pageData.frontmatter.updated
const ogImage = context.pageData.frontmatter.manual_og_image
const tags = context.pageData.frontmatter.tags || []
const type = context.page.startsWith('blog/') ? 'article' : 'website'
const head: HeadConfig[] = [
// Basic
description ? genMeta('description', description) : undefined,
// Open Graph
description ? genMeta('og:description', description) : undefined,
genMeta('og:title', title),
genMeta('og:url', url),
genMeta('og:type', type),
ogImage ? genMeta('og:image', `https://jiongks.name/${ogImage}`): undefined,
// Twitter
description ? genMeta('twitter:description', description) : undefined,
genMeta('twitter:title', title),
genMeta('twitter:url', url),
ogImage ? genMeta('twitter:image', `https://jiongks.name/${ogImage}`): undefined,
genMeta('twitter:card', ogImage ? 'summary_large_image' : 'summary'),
// Article
published ? genMeta('article:published_time', published) : undefined,
updated ? genMeta('article:modified_time', updated) : undefined,
...tags.map((tag: string) => genMeta('article:tag', tag)),
].filter(Boolean)
return head
},最终生成的代码如下:
<!DOCTYPE html>
<html lang="zh-CN" dir="ltr">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>中文格式化小工具 zhlint 及其开发心得 | 囧克斯</title>
...
<meta name="description" content="介绍要给小工具给大家:**zhlint** zhlint logo 这个工具可以帮助你快速格式化中文或中英混排的文本。比如常见的中英文之间要不要用空格、标点符号要用全角字符之类的。 看上去这工具似乎和自己的工作和职业关系不大,但其实也是有一定由来的。 项目的由来 自己之前参与过一些 W3C 规范的翻译工作,这其中除了需要一定的词汇量、语法知识和表达技巧之外,最主要的部分应该就是格式了。因为大...">
<meta name="og:description" content="介绍要给小工具给大家:**zhlint** zhlint logo 这个工具可以帮助你快速格式化中文或中英混排的文本。比如常见的中英文之间要不要用空格、标点符号要用全角字符之类的。 看上去这工具似乎和自己的工作和职业关系不大,但其实也是有一定由来的。 项目的由来 自己之前参与过一些 W3C 规范的翻译工作,这其中除了需要一定的词汇量、语法知识和表达技巧之外,最主要的部分应该就是格式了。因为大...">
<meta name="og:title" content="中文格式化小工具 zhlint 及其开发心得">
<meta name="og:url" content="https://jiongks.name/blog/introducing-zhlint">
<meta name="og:type" content="article">
<meta name="og:image" content="https://jiongks.name/og/introducing-zhlint.png">
<meta name="twitter:description" content="介绍要给小工具给大家:**zhlint** zhlint logo 这个工具可以帮助你快速格式化中文或中英混排的文本。比如常见的中英文之间要不要用空格、标点符号要用全角字符之类的。 看上去这工具似乎和自己的工作和职业关系不大,但其实也是有一定由来的。 项目的由来 自己之前参与过一些 W3C 规范的翻译工作,这其中除了需要一定的词汇量、语法知识和表达技巧之外,最主要的部分应该就是格式了。因为大...">
<meta name="twitter:title" content="中文格式化小工具 zhlint 及其开发心得">
<meta name="twitter:url" content="https://jiongks.name/blog/introducing-zhlint">
<meta name="twitter:image" content="https://jiongks.name/og/introducing-zhlint.png">
<meta name="twitter:card" content="summary_large_image">
<meta name="article:published_time" content="2020/04/26 03:53:59">
<meta name="article:modified_time" content="2020/04/27 12:29:56">
<meta name="article:tag" content="Chinese">
<meta name="article:tag" content="lint">
<meta name="article:tag" content="tool">
</head>
<body>
...最后处理了两个 Vue Blog 样式上的小问题:
Dark mode (中文翻译是夜间模式?暗黑模式?深色模式?) 下
<mark>标签内默认的文字配色有问题,我做了简单的修复。css/* fix color theme in <mark>s */ .dark\:prose-invert mark a, .dark\:prose-invert mark strong, .dark\:prose-invert mark code { color: #111827; }为了避免过长的 URL 无法折行导致页面布局被破坏,我在必要的地方加了
word-break: keep-all,对应的 Tailwind class 是break-all(2014-07-15 更新:仅在必要的 URL 前后包裹了一层<span class="break-all">...</span>,把负面影响降到了最低)。
最后的最后支持了一下统计代码和 RSS 订阅文件 (这个 Vue Blog 就有,我做了些微调,沿用了我的博客站之前的输出格式),大功告成。
简单回顾一下,有几个 config 字段在整个迁移过程中起到了关键的作用,它们基本都在 build hooks 分类里。如果你也有类似的旧版本迁移或想给自己的网站定制一些特殊的功能,可以留意:
transformPageData():预处理页面数据,比如早期的评论transformHead():预处理<head>标签内的内容,比如<meta>transformHtml():后处理<body>标签内的内容,比如<meta>去重buildEnd():后处理全站的 HTML 内容,比如 RSS 订阅文件
锦上添花
把该迁移的都迁移完毕过后,我又想了想,能不能顺便再给自己的网站加点什么呢?于是我又做了几个小功能:
manual_og_image:这个字段是用来在<meta>里指向文章缩略图的,上一节其实已经提到过了,其实算是个新东西,之前没有仔细弄过。不重复介绍了。View transitions:这是一个相对较新的 W3C 规范,用来定制页面跳转之间的动画。关键代码片段:
vue<script setup> import { useRouter } from 'vitepress' const router = useRouter() router.onBeforePageLoad = async () => { if ((document as any).startViewTransition) { await (document as any).startViewTransition() } } </script> <template>...</template> <style> #app { view-transition-name: app; } @keyframes fade-in { from { opacity: 0; transform-origin: bottom center; transform: rotate(-5deg); } } @keyframes fade-out { to { opacity: 0; transform-origin: bottom center; transform: rotate(5deg); } } ::view-transition-old(app) { animation-name: fade-out; /* Ease-out Back. Overshoots. */ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1.275); } ::view-transition-new(app) { animation-name: fade-in; /* Ease-out Back. Overshoots. */ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1.275); } </style>动图效果:

Progress animations:这是一个更新的 W3C 规范,用来定制各种和滚动条进度自动绑定的动画效果。关键代码片段:
vue<template> <div class="progress" /> </template> <style> /* progress animations */ .progress { height: 4px; background: transparent; position: fixed; bottom: 0; left: 0; width: 100%; transform-origin: 0 50%; animation: scaleProgress auto linear, colorChange auto linear; animation-timeline: scroll(root); } @keyframes scaleProgress { 0% { transform: scaleX(0); } 100% { transform: scaleX(1); } } @keyframes colorChange { 0% { background-color: blue; } 50% { background-color: yellow; } 100% { background-color: red; } } </style>动图效果:
外链预览图:这是我效仿 WikiPedia 中词条链接的效果,用来在鼠标悬停在外部链接上时显示一个预览图,以方便用户更好地预判要不要将其打开。我用了 floating-vue 这个库,结合一个三方的缩略图生成服务实现的。实际体验够不够好还有待观察。
以上就是我近期对自己的网站做的一些小改动,希望能给你一些启发。如果你也有类似的需求,不妨参考一下我的做法。如果你有更好的想法,欢迎在评论区留言。
相关链接: